고정 헤더 영역
상세 컨텐츠
본문
반응형
이전 글의 내용과 연결되는 글이라서 이전 글을 보지 않았다면 이 글을 참고하길 바란다.
3. Spring Batch + 멱등성 있게 처리하기
2번을 적용한 이유 속도가 빨라져서 만족하고 있었지만 업데이트되지 않는 사용자도 계속 업데이트하는 것은 비효율적이라고 생각했다.
그러는 도중에 일주일 동안 클릭 카운트의 히스토리도 적용하자는 이야기가 있었다.
그래서 아예 일일 클릭 카운트를 저장해서 그 일일 카운트에 등록된 사용자만 업데이트한다면 문제가 없을 것 같았다.
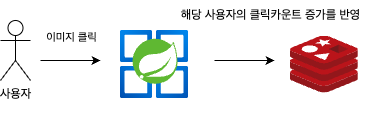
기존 로직은 위의 이미지처럼 사용자가 이미지를 클릭하면 서버에서 redis에 지정된 sorted sets 자료구조에 해당 사용자의 클릭 카운트를 증가시킨다.
하지만 추가된 로직에서는 아래와 같이 이미지를 클릭할 때 다른 sorted sets에 일일 클릭 카운트를 따로 반영했다.
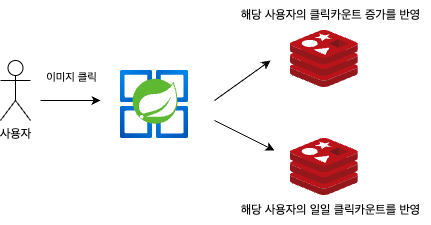
이와 같이 했을 때 어떤 이점을 가져올 수 있을까?
첫 번째로는 당일에 클릭 카운트가 업데이트된 유저를 따로 기록해두기 때문에 전체 데이터를 업데이트할 필요가 없어졌다.
두 번째로는 기존에 데이터를 업데이트하다가 실패하면 처음부터 다시 해야 했지만 sorted sets을 통해 항상 같은 값을 반환받을 수 있다.
그래서 중간에 실패했다면 실패한 데이터부터 다시 업데이트를 실행할 수 있다.
public class RedisPagingItemReader implements ItemStreamReader<TypedTuple<String>> {
private static final int MEMBER_COUNT = 1000;
private final String key;
private final RedisTemplate<String, String> redisTemplate;
private long offset = 0;
private Queue<TypedTuple<String>> items = new LinkedList<>();
public RedisPagingItemReader(String key, RedisTemplate<String, String> redisTemplate) {
this.key = key;
this.redisTemplate = redisTemplate;
}
@Override
public TypedTuple<String> read() {
if (items.isEmpty()) {
fetchNextPage();
}
return items.poll();
}
private void fetchNextPage() {
Set<TypedTuple<String>> page = redisTemplate.opsForZSet().rangeWithScores(key, offset, offset + MEMBER_COUNT - 1);
if (page != null && !page.isEmpty()) {
items.addAll(page);
offset += page.size(); // 페이지를 읽은 후 offset 업데이트
}
}
@Override
public void open(ExecutionContext executionContext) {
if (executionContext.containsKey("offset")) {
offset = executionContext.getLong("offset");
}
}
@Override
public void update(ExecutionContext executionContext) {
executionContext.putLong("offset", offset);
}
}위의 코드를 보면 offset을 기준으로 1000개씩 데이터를 읽고 있다 그리고 executionContext에 offset 값을 기록한다.
만약 스프링 배치가 중간에 실패하더라도 해당 offset 값부터 다시 시작한다.
이미 일일 클릭 카운트가 sorted sets으로 정렬되어 있기 때문에 offset 값으로 데이터를 읽으면 늘 동일한 결과를 반환한다.
따라서 멱등성 있는 읽기를 통해 늘 동일한 결과를 만들 수 있게 되었다. 그리고 전체 데이터를 업데이트하지 않고 원하는 데이터만 업데이트할 수 있게 되었다.
여기서 끝이고 싶지만 로직도 늘어나고 offset을 통한 데이터 읽기가 속도가 그리 빠르지 않다는 것이다.
@Bean
@StepScope
public ItemProcessor<TypedTuple<String>, Pair<UpsertMember, DailyClickCount>> processor(
@Value("#{jobParameters['createAt']}") final String createAt
) {
return tuple -> {
final String name = tuple.getValue();
Long clickCount = heartRepository.getClickCount(name);
return Pair.of(
new UpsertMember(name, clickCount),
new DailyClickCount(name, LocalDate.parse(createAt), tuple.getScore().longValue())
);
};
}processor 부분도 위와 같이 변경되었다. 기존에는 클릭 카운트 사용자만 만들었다면 이제는 일일 클릭 카운트도 만든다.
속도는 어떻게 변했을까?
| rows | 스케줄링 | 스프링 배치 | offset |
|---|---|---|---|
| 10,000 | 7.3초 | 1.2 초 | 9.12초 |
| 50,000 | 23.58초 | 2.33초 | 25.12초 |
| 100,000 | 57.78초 | 3.76초 | 48.32초 |
| 500,000 | 4분 19초 | 14.98초 | 3분 1초 |
| 1,000,000 | 9분 17초 | 29.58초 | 8분 29초 |
| 5,000,000 | 46분 32초 | 6분 24초 | 46분 12초 |
오히려 배치를 사용하지 않은 스케줄링 방식과 속도가 비슷해졌다. 어떠한 개선점이 필요했다.
어떤 방법이 있을까?
4. Spring Batch 파티셔닝 적용
파티셔닝은 Spring Batch의 대표적인 Scalling 기능이다.
대규모 데이터를 처리하면 서버를 Scalling 하듯 배치 애플리케이션도 확장이 필요하다.
그중 파티셔닝은 매니저 Step이 대량의 데이터 처리를 위해 지정된 수의 Worker Step으로 분할 처리하는 방법이다.
파티셔닝 (Partitioning)와 같은 Spring Batch의 Scalling 기능을 사용하는 이유는, 기존의 코드 변경 없이 성능을 향상시키기 위함이다.
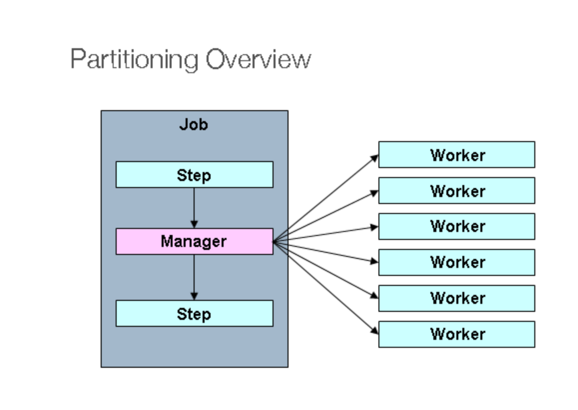
코드를 살펴보기 전 내용부터 설명하자면 크게 변한 부분은 partitioner, stepManager, executor가 추가되었다는 것이다.
Partitioner
Partitioner 인터페이스는 파티셔닝된 Worker Step을 위한 Step Executions을 생성하는 인터페이스다.
인터페이스가 갖고 있는 메소드는 1개로 partition(int gridSize)가 있다.
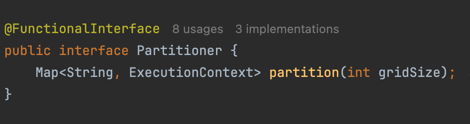
해당 파라미터로 넘기는 gridSize는 몇 개의 StepExecution을 생성할지 결정하는 설정값이다.
일반적으로는 StepExecution 당 1개의 Worker Step를 매핑하기 때문에 Worker Step의 수와 마찬가지로 보기도 한다.
Spring Batch에서 기본적으로 1로 둔다. 이를 변경하기 위해서는 PartitionHandler 등을 통해서 변경 가능하다.
여기서는 stepManager에 설정해 주었다.
다만, 이렇게 gridSize만 지정했다고 하여, Worker Step이 자동으로 구성되진 않는다.
해당 gridSize를 이용하여 각 Worker Step마다 어떤 Step Executions 환경을 갖게 할지는 오로지 개발자들의 몫이다.
StepManager
매니저 스텝은 Worker Step를 어떻게 다룰지를 정의한다.
이를테면, 어느 Step을 Worker step의 코드로 두고 병렬로 실행하게할지, 병렬로 실행한다면 쓰레드풀 관리는 어떻게 할지,gridSize는 몇으로 둘지 등등을 비롯하여 모든 작업이 완료되었는지를 식별하는지를 다룬다.
@Bean
public Step stepManager(@Qualifier("syncRedisToMySqlStep") Step partitionStep, JobRepository jobRepository) {
return new StepBuilder("stepManager", jobRepository)
.partitioner("syncRedisToMySqlStep", partitioner()) //1
.step(partitionStep)
.gridSize(PARTITION_SIZE) // 파티션 수
.taskExecutor(executor())
.build();
}(1) partitioner("syncRedisToMySqlStep", partitioner())
- 코드를 살펴보면 기존 정의했던 syncRedisToMySqlStep을 Worker로 지정하여 Partitioner 구현체를 등록한다.
- 해당 코드에서는 같은 클래스 내의 partitioner 메서드를 통해서 생성했기 때문에 해당 메소드로 호출한다.
(2) step(partitionStep)
- 파티셔닝될 Step을 등록한다.
- partitionStep이 Partitioner 로직에 따라 서로 다른 StepExecutions를 가진 여러개로 생성된다.
(3) gridSize(PARTITION_SIZE)
- 몇 개의 StepExecution을 생성할지 결정하는 설정값이다.
(4) taskExecutor(executor())
- 멀티쓰레드로 실행하기 위해 TaskExecutor 를 지정한다.
@Bean
public TaskExecutor executor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(POOL_SIZE);
executor.setMaxPoolSize(POOL_SIZE);
executor.setThreadNamePrefix("partition-thread");
executor.setWaitForTasksToCompleteOnShutdown(Boolean.TRUE);
executor.initialize();
return executor;
}해당 코드가 executor코드이다.
쓰레드풀 내에서 지정된 갯수만큼의 쓰레드만 생성할 수 있도록 ThreadPoolTaskExecutor를 사용했다.
마지막으로 Partitioner코드에 중요한 부분을 살펴보면
public class RedisRangePartitioner implements Partitioner {
...
private Map<String, ExecutionContext> createPartitionForLargeData(long size, int gridSize) {
long range = size / gridSize;
long remainder = size % gridSize;
Map<String, ExecutionContext> result = new HashMap<>();
long startOffset = 0;
long endOffset = range - 1;
for (int i = 0; i < gridSize; i++) {
if (i < remainder) {
endOffset++;
}
ExecutionContext value = new ExecutionContext();
value.putLong("startOffset", startOffset);
value.putLong("endOffset", endOffset);
result.put("partition" + i, value);
startOffset = endOffset + 1;
endOffset += range;
}
return result;
}
...
}전체 업데이트해야할 사이즈를 가져온 후 이를 gridSize에 맞게 각 파티션 ExecutionContext으로 할당한다.
@Test
void gridSize에_맞게_offset이_분할된다() {
레디스에_데이터_넣기(10);
final RedisRangePartitioner redisRangePartitioner = new RedisRangePartitioner(KEY, redisTemplate);
final Map<String, ExecutionContext> executionContextMap = redisRangePartitioner.partition(5);
final ExecutionContext partition1 = executionContextMap.get("partition0");
assertThat(partition1.getLong("startOffset")).isEqualTo(0L);
assertThat(partition1.getLong("endOffset")).isEqualTo(1L);
final ExecutionContext partition5 = executionContextMap.get("partition4");
assertThat(partition5.getLong("startOffset")).isEqualTo(8L);
assertThat(partition5.getLong("endOffset")).isEqualTo(9L);
}해당 테스트 코드를 돌려보면 아래와 같이 데이터가 나눠진 것을 볼 수 있다.
partition0 (startOffset:0, endOffset:1)
partition1 (startOffset:2, endOffset:3)
partition2 (startOffset:4, endOffset:5)
partition3 (startOffset:6, endOffset:7)
partition4 (startOffset:8, endOffset:9)이렇게 RedisRangePartitioner 통해 생성된 ExecutionContext에 맞춰 Worker Step들이 생성되어 그들의 Step Executions이 된다.
ItemReader
@Bean
@StepScope
public ItemStreamReader<TypedTuple<String>> reader(
@Value("#{stepExecutionContext[startOffset]}") Long startOffset,
@Value("#{stepExecutionContext[endOffset]}") Long endOffset
) {
final String key = RedisKeyGenerator.getDailyClickCountKey();
return new RedisPagingItemReader(key, redisTemplate, startOffset, endOffset);
}위에서 RedisRangePartitioner를 통해 stepExecutionContext에 startOffset과 endOffset이 등록되어 있으니 해당 값을 사용한다.
전체 코드
@Slf4j
@Configuration
@RequiredArgsConstructor
@ConditionalOnProperty(value = "spring.batch.job.name", havingValue = "syncRedisToMysqlJob")
public class MemberUpsertJobConfig {
private static final int POOL_SIZE = 10;
private static final int PARTITION_SIZE = 10;
private static final int CHUCK_SIZE = 1000;
private static final String STEP_NAME = "syncRedisToMysqlStep";
private static final String JOB_NAME = "syncRedisToMysqlJob";
private final RedisTemplate<String, String> redisTemplate;
private final MemberRepository memberRepository;
private final HeartRepository heartRepository;
private final MemberUpsertAfterJobListener memberUpsertAfterJobListener;
@Bean
public Job syncRedisToMysqlJob(@Qualifier("stepManager") final Step stepManager,
final JobRepository jobRepository) {
return new JobBuilder(JOB_NAME, jobRepository)
.incrementer(new RunIdIncrementer())
.flow(stepManager)
.end()
.listener(memberUpsertAfterJobListener)
.build();
}
@Bean
public Step stepManager(@Qualifier("syncRedisToMySqlStep") Step partitionStep, JobRepository jobRepository) {
return new StepBuilder("stepManager", jobRepository)
.partitioner("syncRedisToMySqlStep", partitioner())
.step(partitionStep)
.gridSize(PARTITION_SIZE) // 파티션 수
.taskExecutor(executor())
.build();
}
@Bean
@StepScope
public Partitioner partitioner() {
return new RedisRangePartitioner(RedisKeyGenerator.getDailyClickCountKey(), redisTemplate);
}
@Bean
public Step syncRedisToMySqlStep(final ItemReader<TypedTuple<String>> reader,
final ItemWriter<Pair<UpsertMember, DailyClickCount>> writer,
final ItemProcessor<TypedTuple<String>, Pair<UpsertMember, DailyClickCount>> processor,
final JobRepository jobRepository,
final PlatformTransactionManager transactionManager) {
return new StepBuilder(STEP_NAME, jobRepository)
.<TypedTuple<String>, Pair<UpsertMember, DailyClickCount>>chunk(CHUCK_SIZE, transactionManager)
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}
@Bean
public TaskExecutor executor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(POOL_SIZE);
executor.setMaxPoolSize(POOL_SIZE);
executor.setThreadNamePrefix("partition-thread");
executor.setWaitForTasksToCompleteOnShutdown(Boolean.TRUE);
executor.initialize();
return executor;
}
@Bean
@StepScope
public ItemStreamReader<TypedTuple<String>> reader(
@Value("#{stepExecutionContext[startOffset]}") Long startOffset,
@Value("#{stepExecutionContext[endOffset]}") Long endOffset
) {
final String key = RedisKeyGenerator.getDailyClickCountKey();
return new RedisPagingItemReader(key, redisTemplate, startOffset, endOffset);
}
@Bean
@StepScope
public ItemProcessor<TypedTuple<String>, Pair<UpsertMember, DailyClickCount>> processor(
@Value("#{jobParameters['createAt']}") final String createAt
) {
return tuple -> {
final String name = tuple.getValue();
Long clickCount = heartRepository.getClickCount(name);
return Pair.of(
new UpsertMember(name, clickCount),
new DailyClickCount(name, LocalDate.parse(createAt), tuple.getScore().longValue())
);
};
}
@Bean
@StepScope
public ItemWriter<Pair<UpsertMember, DailyClickCount>> writer() {
return new MysqlItemWriter(memberRepository);
}
}그렇다면 성능이 어떻게 변했을까?
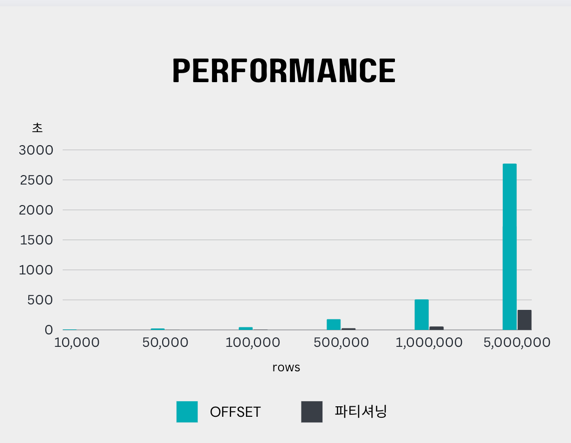
| rows | 스케줄링 | 스프링 배치 | offset | 파티셔닝 |
|---|---|---|---|---|
| 10,000 | 7.3초 | 1.2 초 | 9.12초 | 1.1초 |
| 50,000 | 23.58초 | 2.33초 | 25.12초 | 3.80초 |
| 100,000 | 57.78초 | 3.76초 | 48.32초 | 6.23초 |
| 500,000 | 4분 19초 | 14.98초 | 3분 1초 | 30.1초 |
| 1,000,000 | 9분 17초 | 29.58초 | 8분 29초 | 57.13초 |
| 5,000,000 | 46분 32초 | 6분 24초 | 46분 12초 | 5분 35초 |
2번째로 했던 스프링 배치 속도와 같아졌다. 오히려 로직은 늘어났으니 더 빨라졌다고 할 수 있다.
다만 파티셔닝을 적용할 경우 기존에 실패했던 데이터부터 다시 시작할 수는 없다.
그럼에도 얻는 이점은 분명히 존재한다. 만약 500만 명의 사용자가 사용한다 했을 때 실질적인 일일 사용자는 10~20% 정도뿐이다.
그럴 경우 50만~100만의 사용자의 데이터만 업데이트하면 되는데 그건 둘 다 1분 안에 해결이 되기 때문에 충분하다고 판단했다.
마무리
이렇게 스케줄링 방식으로 시작해서 스프링 배치를 사용하면서 점점 발전시켜나갔다.
속도 개선과 불필요한 데이터 업데이트를 막기 위해 다양한 방법으로 바꾸었다.
그러면서 파티셔닝까지 적용했는데 기존 스프링 배치 step을 작성했던 코드가 있다면 해당 Step의 코드는 변경 없이 매니저 Step만 추가하여 파티셔닝을 적용할 수 있다.
해당 코드는 여기에서 확인 가능하다.
'프로젝트 > click-me' 카테고리의 다른 글
| Spring Batch 파티셔닝 적용후 JVM이 종료되지 않는 문제 해결 (0) | 2024.05.03 |
|---|---|
| Redis의 클릭 카운트 MySQL로 데이터 동기화 (1) (0) | 2023.12.15 |
| Docker와 Kubernetes를 이용한 GKE 환경에서의 CI/CD 구현 (0) | 2023.12.05 |
| Jib을 이용한 CD 최적화: Layer 캐싱 활용 (0) | 2023.11.30 |
| github에서 README.md이미지 업데이트 문제: Camo와 캐싱 이슈 해결하기 (0) | 2023.10.20 |




